
To top off our intensive three-month-long experience at NYCDSA, we chose to assist a US travel recommendation start-up by implementing intelligence and automation into their operations, to save hours of manual work. The company targets prospective travelers living in the US who know approximately when they’d like to take a trip within the country, but would like to be recommended exact location and itinerary ideas, rather than already know where exactly they’d like to go. Similar to Netflix, the company’s website is designed to get to know users so that curated recommendations can be given to them for their vacations. Upon navigating to the website, users fill out a short quiz, including prompts that ask them to select which images inspire them and what kinds of activities they enjoy when traveling. They also fill out approximately how soon they’d like to travel (e.g. “3-6 months from now”). After a user completes the quiz, the company sends an email over, containing 3 separate trip ideas, which are based around events happening during the specified time window. For example, if it is evident that a certain user’s preferred trip includes live shows, their itineraries will include events tagged with the category “Arts & Entertainment”. Since the trip recommendations are centered around linking user profiles to recurring events that happen around the country, categorizing these events accurately and efficiently is key. After speaking to the start-up founder, it was clear that we’d have a few interesting tasks to explore in our project:
- Automate the process of categorizing new events added to the company database.
- Find a new event categorization scheme intelligently.
- Automate the end-to-end process of taking in user inputs and outputting appropriate event recommendations from the database.
To tackle task #1, the current labelling scheme would be used and predicted using supervised classification models. Task #2, on the other hand, would involve reconstructing the categories and perhaps finding more specific ones, using unsupervised clustering techniques to find structure in the event data from scratch. After finalizing event tags, end-to-end automation could be simulated rather simply by filtering events out of the database that match with specified inputs. We decided to primarily focus on the first two tasks, since full-on automation would require more integration with the rest of the platform, including making potential changes to the website’s front-end.
We were given access to the company’s compiled event database, which includes details for about 2000 events around the US, including location data, the event’s recurring annual timeframe, event title, event description, and more. It also includes an event category column which the company manually filled in with one of four categories for each event: Arts & Entertainment, Active, Tastebuds, and Learn.
Since we started off with the manual entries of categories for these 2000 events, our first supervised task was straightforward: to train a model on a portion of the event data and test it on the rest in order to predict these categories. With an accurate enough supervised model, new events would be categorized according to this scheme without much manual intervention.
Preprocessing
In order to properly analyze the event descriptions using natural language processing techniques, we started with classic text preprocessing methods. We first decided to concatenate the event titles with their corresponding descriptions so that the model would treat these as one combined feature when classifying events. We then cleaned the newly generated description texts to remove punctuation and special characters. Our next task was to remove stopwords, or transitory words that wouldn’t tell us more about what each event was about. In addition to filtering out the general dictionary of English stopwords that comes with Python’s natural language toolkit (NLTK), we also removed certain words that were present in nearly every event, but didn’t add any detail to the event description. These were words that just described the presence of an event (“event”, “festival”, “celebration”), and time-specific words referring to whether an event took place during a specific month or week (although we kept words that referred to specific seasons). After this, we chose to lemmatize the remaining words within each event description, so that words of the same root were reduced to the same root word, rather than being counted as differing ideas. For example, “Drink”, “Drinks”, and “Drank” would all be processed down to their root word “Drink” in this instance. This allowed us to be more sure that the frequency of a specific word, as it relates to the theme of an event, would be represented accurately.
Exploratory Data Analysis
Once our text was processed, it was time to start analyzing it. We decided to begin by creating a simple word cloud in order to visualize the most frequently appearing words within all the events.
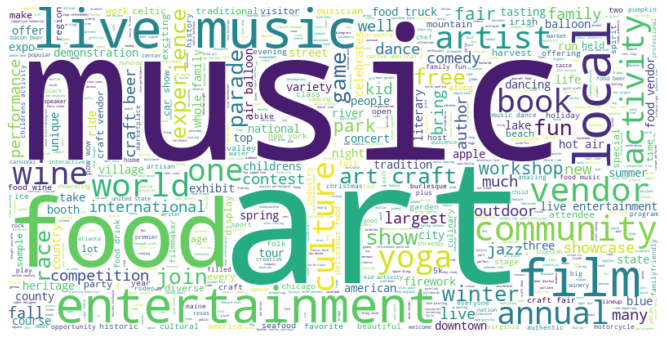
Our word cloud convinced us to look at word frequency a bit more carefully, since “music” “art” and “food” largely dominated the frequency tallies. By putting all the event descriptions into one text-blob, and then converting that text-blob into a dictionary with the words as keys and their frequencies as values, we were able to look at word frequencies as proportions of the total word count. Sure enough, the top 5 words in all event descriptions (“music”, “food”, “art”, “live”, “craft”) made up 35% of all the words left in our event descriptions after preprocessing. The top 10 words made up 54% of all the words. Additionally, the spread of the top words in each event was important to analyze. We realized that while events that were music-specific had the word “music” in them, there were also events that mentioned the word music without being predominantly focused on music. For example, an art gallery event may include a live performance by a local string quartet. We also found that the top 5 most frequent words each occurred in more than 20% of events, sometimes as high as 30% of events. To avoid concept dilution, we decided to look at the amount of times each of these top five words occurred throughout each event, relative to all events. This is performed in TF*IDF vectorization, which we explored in the next step.
Automation of Event Labeling
With our preprocessed data ready, we were ready to tackle our first main task: automating the categorization of events using the current classification scheme. To do so, we explored two supervised learning classification methods: Naive Bayes and Doc2Vec.
Naive Bayes
In order to apply any predictive models to our data, we first needed to convert it from text format to a format a machine would understand--numerical vectors. This process is called vectorization. There are several flavors of vectorization, but we tried two: plain count vectorization (also known as the “bag of words” method), and TF*IDF vectorization. Using a count vectorizer with our event data, we generated a word frequency matrix, where each row represents one event description, and each column represents one of the words present in the entire event corpus. The values of the matrix represent the count of a particular word (column value) in an event description (row value). TF*IDF vectorization works almost the same way, except it incorporates a penalization method to mitigate the effects of highly-present words on the model; TF, standing for the total frequency of a word in an event, is multiplied by IDF, or the inverse document frequency of that word, which will reduce term frequency more if the word’s frequency across all the documents is high. We built two separate Naive Bayes models using each of these vectorization techniques in order to compare their performances before choosing a final one; we hypothesized in advance that TF*IDF vectorization would do better with our data because of its mitigation of our highly present words.
With our vectorized matrices ready, we started building our first predictive model: a Naive Bayes classifier. A Naive Bayes classifier utilizes conditional probabilities and Bayes’ Theorem to analyze previous classifications and to then calculate the probability that a new data point belongs to a certain class. For example, after calculating the probability that the word “run” appears in an “Active” event, the model calculates the reverse probability that a new event description containing the word “run” should belong to the “Active” category, by combining the conditional probabilities of each word in the description. This method is called “naive” because it assumes an independence of its tokens and treats them as a simple bag of words with no grammar rules. However, for our purposes of figuring out the topic of an event based on the appearance of words rather than wording styles, this classifier is especially appropriate. Furthermore, we chose to implement a multinomial version of the classifier, which means the model looks at word count in each event description rather than just whether a word was present at all or not (binomial), since a higher frequency of a word might imply stronger relevance to the event.
Finally, we used cross-validation to randomly split our data into 5 different folds so that the model could be trained and tested on 5 different combinations of data, to reduce potential noise dependence. The aggregated results for our TF*IDF vectorized multinomial Naive Bayes model were as follows:

To break down this set of scores, we’ll start with the precision column. This describes the proportion of events categorized as a certain category that indeed should’ve been under that category. A nuanced difference is described by recall, which is the proportion of a certain category’s events being correctly categorized as that category, rather than ending up in a different category. For example, 78% of the model’s guesses for Arts & Entertainment were indeed supposed to be that, while 22% of those should’ve been guessed as other categories (precision); 74% of actual Arts & Entertainment events were guessed by the model to be under that category, while 26% ended up being guessed as other categories (recall). The f1-score column simply aggregates the precision and recall accuracy measures by taking their mean, and the accuracy row of the chart takes the average of all the f1 scores, providing an overall estimate of the model’s accuracy: 74%. It’s worth noting that the model using regular count vectorization produced a very comparable score.
Doc2Vec
Another method we explored to both classify and cluster events was Doc2Vec, a machine learning technique often used in autocorrect technology. The algorithm uses a continuous bag of words - a sliding window of words in each document - in order to make probabilistic predictions about the most likely words that occur before and after each word in a given document. The probability of the preceding and following words allow us to look at the presence of specific words in the context of a sentence or a full event description, and can associate specific words or phrases with a class based on where and how that word or phrase appears in the description. We would then measure differences in context through cosine distance - once our contextual associations are converted into a series of vectors, we would look to see the angle between a vector representing one phrase, and a vector representing another. Words and phrases that were closer in context would have a smaller angle between their respective vectors, and therefore a higher score. We believed a context-based approach to looking at each event description would be able to classify events more accurately, given that the overwhelming presence of specific words out of context might throw off our classifications. We also attempted to cluster events based on context. By using hierarchical clustering methods, and bucketing event descriptions together based on how similar they were in context, we were hoping to find groups of events that were closely related by the specific word orderings or phrases used in the event text. This, ideally, would group events together by how words were used, not just by what words were used.
Unfortunately, this method wasn’t giving us useful results. We theorized that because of our necessary pre-processing, the event descriptions themselves were shrunk so much that the algorithm wasn’t able to infer different contexts from different event descriptions. Because the algorithm wasn’t able to differentiate between events based on limited words used to infer context, the cosine distance between somewhat different events wound up being very small, meaning that our model would guess that events were similar to each other when they weren’t. The cosine distance between many event descriptions was so similar, that our model would only be able to correctly classify an event around 50% of the time. Furthermore, this led to problems with hierarchical clustering as well. Since this clustering method was meant to group events together based on similar cosine distance, and our model assumed that many events had very similar cosine distances, the clustering method grouped most events together into one large cluster. We wound up having one large cluster with 80% of all event descriptions put inside of it, and 9 clusters made up of mostly outliers representing the other 20%. With context-based prediction and clustering methods failing to give us useful results, we turned back to our frequency-based methods.
Classification Threshold
Our final prediction model is able to return a class prediction based on a probability distribution - for each of the four classes, the model assigns a percentage likelihood that an event belongs to a specific class, based on the frequency of specific words in the description. The class that receives the highest percentage likelihood is our prediction. However, because event descriptions can often include words that are associated with multiple classes, the best prediction might not always have a high probability associated with it. If an event seems equally likely to belong to three out of the four classes, for example, the percentage likelihood that an event belongs to each class will be about 33.3% for each. This raised two important questions: is there a cutoff point where the probability is too low, and we don’t classify an event into a specific category? And what is the ideal cutoff point? To answer both of these questions, we built a tool to check the tradeoff between misclassification and non-classification (assigning no class based on a low probability) as we approached different cutoff points.
Our tool first split up our model’s training and test data via 10-fold cross-validation, to ensure best fit. Once we ran our model on each split dataset, and received probability values associated with each prediction, our tool began to actually classify events based on this probability distribution. What was different from our normal predictive model is that we were able to assign a “cutoff probability” between 0% and 100%. If the highest percentage likelihood of an event fell below that cutoff, the event was not put into any class, and received a “none” value. If our cutoff was 50%, for example, and the highest percentage likelihood that an event received was 45%, that event would not be classified. From there, our tool was able to tally correct, incorrect, and “none” classifications, across a range of cutoff probabilities, in order to see the tradeoff between misclassification and non-classification as the cutoff probability got higher. The following represents this tradeoff graphically:

It stands to reason that if an event has 4 classes, and our algorithm was completely unsure how to classify it, it would assign each class an equal percentage likelihood of 25%. So any cutoff rate 25% and below was not considered. One is able to see from this graph that at a 40% cutoff rate, our non-classifications match our misclassifications, meaning that you’re equally as likely to not assign an event to a specific class as you are to misclassify an event at this cutoff point, The number of correct guesses remains fairly high as well. Based on this analysis, we were able to confidently recommend that one should only classify an event based on their percent likelihood if that event is 40% or more likely to be in that class, relative to all the others. This cutoff point has a very interesting application in multi-class classification as well. If an event is 70% likely to be in class A, but only 30% likely to be in class B, our cutoff threshold suggests that you should only classify the event as class A. However, if an event is 55% likely to be in class A, and 45% likely to be in class B, you could classify an event into both class A and class B. Given the categories that the owner of this company was using to classify events (A&E, Tastebuds, Learn, Active), sometimes it might make sense to classify an event into two buckets rather than one based on this probability distribution (an event might fit the description for A&E and Tastebuds at the same time, for example.)
Finding New Categories
After developing a successful supervised predictive classifier, we were excited to try detecting a new clustering scheme altogether for the classifier to predict on. As mentioned previously, we explored Doc2Vec for this purpose, but it didn’t end up working well with our data to generate meaningful clusters. We then tried another unsupervised learning method called Latent Dirichlet Allocation (LDA). This is a popular technique for topic modeling, or clustering text data by topic. In short, it creates a user-specified amount of topic clusters based on likelihoods of term co-occurrences, rather than semantic definitions. Each topic is modeled as a distribution of words, and each document is modeled as a distribution of the created topics. Because we cared about mitigating the effects of overly common words just like earlier, we cut out any words that appeared in more than 20% of events (which essentially cut out “music”, “food”, and “live”). We also applied TF*IDF to word frequency values like before. The following visualization depicts an LDA model we fine-tuned after playing around with different parameter combinations and ideas:

Shown here, 6 topic clusters were created by the LDA model, and topic “5” is defined as a frequency distribution of the words in the event data, with relatively high appearances of the words shown above. Scanning all the words that made it to this top-30 list, we noticed a good amount of food-related words (bacon, wine, chocolate, gluten, sweet, chef), especially compared to the distributions of the other clusters. After evaluating each cluster’s word distribution, we tried coming up with a label for each category that best described the topic being portrayed. Though challenging, finding these labels during the topic modeling process is the human element needed to make sense of the unsupervised model’s distributions. We came up with the following scheme:
- Category 1 - outdoor fairs
- Category 2 - artsy “world” expos
- Category 3 - local/ethnic culture
- Category 4 - physical and mental wellness
- Category 5 - food parties
- Category 6 - southern cultural
Constructing this LDA model was indeed interesting, and something we worked on for a nice chunk of our project time. After showing the finalized categorization scheme to our client, we didn’t feel that it was fitting or robust enough to replace the current categorization scheme. We concluded that using the basic set-up of our LDA model with a larger, more robust database of events in the future might allow it to pick up on more interesting, contrasting patterns. Another interesting future direction might be to hone in on just one of the current categories (perhaps the largest, most general one) in the database and run an LDA model on that subset to divide it into subclusters. This would achieve an increase in total category amounts, and thus a more nuanced categorization theme.
Our Command Line Interface Tool
After working on both supervised and unsupervised models and polishing off a working predictive classifier, we wanted to provide an easy-to-use deliverable to our client that would allow them to quickly feed in new events and receive predictions of the most appropriate categories for them. We built a CLI tool using Python and loaded our models into it by a process called “pickling”. The tool allows users to input a new event description and outputs the probabilities of it belonging to each of the four categories. Different levels of output verbosity can be specified, with ‘2’ being the most verbose on a scale from 0 - 2.

In this example, the user inputted a blurb about a Green Day concert, which the model preprocessed into the shortened text shown. The model then predicted A&E (Arts and Entertainment) as the category with the highest probability to match this event, which is accurate! The probability of .48 is above our calculated threshold of 40%, and thus the user can confidently categorize this event under A&E without concern!
Conclusions & Future Work
It was a pleasure working with our client to tremendously increase their efficiency and introduce automation and machine intelligence into their daily work. While our LDA model may not be put to use right away, it has potential to be improved down the line as the database grows to include a more robust variety of events. A new LDA model can be used to subdivide one or more of the existing clusters as well to provide a more nuanced categorization scheme. Semi-supervised clustering methods, such as “Guided LDA”, are another interesting future direction to explore. Our client was delighted to receive a tool that would automate the categorization of new events, saving hours of work and providing a more seamless pipeline. While we didn’t spend much time on end-to-end automation for the application, we demonstrated that filtering the event database according to user inputs from the front-end can be done without much complication, once a rule-based scheme for matching is decided on and finalized by the company.